
Deze publicatie maakt deel uit van een serie over hoe kunstmatige intelligentie het testvak opnieuw uitvindt.
Origineel artikel staat op de Praegus Substack: https://buggedorblessed.substack.com/p/voorbij-automatisering-de-nieuwe-b76
Misschien heb je de naam al voorbij zien komen in je feed. Op 9 maart 2026 maakte OpenAI bekend dat het promptfoo overneemt. Een AI-beveiligingsplatform dat ontwikkelaars helpt om kwetsbaarheden in AI-systemen op te sporen vóórdat die in productie gaan. De financiële details zijn niet vrijgegeven, maar Promptfoo was gewaardeerd op $86 miljoen en had tools gebouwd die al draaien bij meer dan 25% van de Fortune 500-bedrijven.
Bron: OpenAI officieel persbericht
Onderkant formulier
Wat doet Promptfoo eigenlijk?
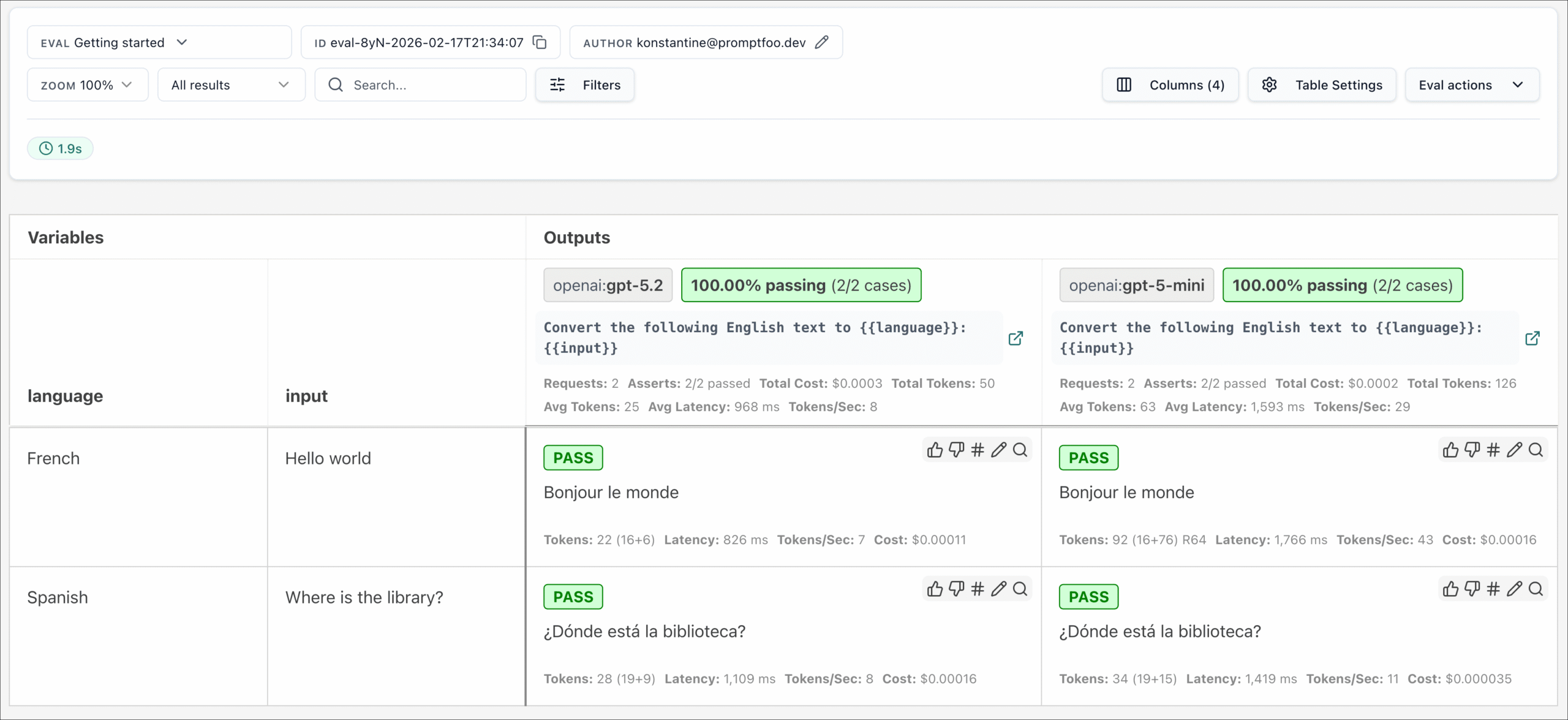
Kort gezegd: Promptfoo is een evaluatie- en beveiligingstool voor LLM-applicaties. Het laat je systematisch testen hoe een AI-model reageert en of het reageert zoals je wilt.
Dat klinkt abstract, dus concreet betekent dit:
LLM evaluatie Je kunt meerdere modellen naast elkaar leggen en ze dezelfde prompts geven. De output vergelijk je op kwaliteit, consistentie en correctheid. Handig als je wilt weten welk model het beste past bij jouw use case of als je wilt valideren of een model na een update nog hetzelfde gedrag vertoont.
Red-teaming Promptfoo simuleert aanvallen op je AI-systeem. Denk aan prompt injections (iemand probeert via een slim geformuleerde invoer het model te manipuleren), jailbreaks of pogingen om gevoelige data uit het model te trekken. Het doet dit geautomatiseerd, direct in je bestaande workflow.
CI/CD integratie Je bouwt de tests in je pipeline. Geen handmatige checks achteraf, de beveiliging en evaluatie zitten er al in vóórdat je deployed. Dat is precies hoe we in het testvak al jaren denken over kwaliteit: shift left, niet patch right.
Compliance en governance Voor enterprises die AI-agents inzetten in echte workflows is dit cruciaal: een vastgelegd bewijs van hoe het model zich gedraagt over tijd. Audittrails, afwijkingen, gedragsveranderingen? Promptfoo maakt het zichtbaar.
Waarom is dit relevant voor testers?
OpenAI integreert Promptfoo in Frontier, hun enterprise platform voor AI-agents. Dat zegt iets, want naarmate AI-agents meer autonomie krijgen en verbonden raken met echte systemen en data, wordt testen van die agents een serieus vakgebied.
En dat is precies het terrein waar jij als tester thuishoort.
De vraag verandert niet zo veel als je denkt. In plaats van “gedraagt de applicatie zich zoals verwacht?” stel je nu de vraag “gedraagt het model zich zoals verwacht, consistent en veilig?”. De denkwijze is dezelfde. De tooling is nieuw.
Promptfoo is een van de eerste tools die dat gat serieus opvult. En het feit dat OpenAI er $86 miljoen voor over had, bevestigt dat dit geen hype is maar noodzakelijke infrastructuur.
Deterministic vs. non-deterministic: waarom testen van AI anders is
Bij traditionele test automation weet je wat je kunt verwachten. Je vult een formulier in, klikt op verzenden en controleert of de juiste melding verschijnt. Hetzelfde scenario, dezelfde invoer, hetzelfde resultaat. Altijd. Dat noemen we deterministic (deterministisch) gedrag en daar zijn onze tools en denkwijzen op gebouwd.
AI-modellen werken anders. Geef een LLM twee keer dezelfde prompt en je krijgt twee keer een andere zin. Misschien inhoudelijk gelijkwaardig, misschien subtiel anders, soms compleet afwijkend. Dat is non-deterministic gedrag en dat gooit het klassieke idee van een geslaagde of gefaalde test behoorlijk overhoop.
Want wat test je dan precies? Je kunt niet meer zeggen: “de output moet exact gelijk zijn aan de verwachte waarde.” Je moet anders gaan denken. Niet wat zegt het model, maar “voldoet de output aan de criteria die ertoe doen?”.
Dat kan zijn: bevat het antwoord geen gevoelige informatie? Blijft het model binnen de afgesproken toon? Geeft het een antwoord in de juiste taal? Weigert het een verzoek dat het zou moeten weigeren?
Dit is waar Promptfoo om de hoek komt. In plaats van exacte string-matching kun je evaluaties definiëren op basis van semantische correctheid, gedragspatronen of expliciete regels. Je beschrijft wat goed gedrag is en Promptfoo toetst daar systematisch aan, over honderden of duizenden testcases tegelijk.
Als tester is dit een mentale switch die je moet maken. Je gaat van controleren of het klopt naar beoordelen of het goed genoeg is. De lat leg je zelf. En dat vraagt om dezelfde kritische denkwijze die je altijd al had — alleen nu toegepast op een output die elke keer net iets anders is.
Voorbeeld 1 — Deterministisch: versienummer ophalen
Een API die een versienummer teruggeeft. De output is altijd exact hetzelfde. Je test op een exacte string-match.
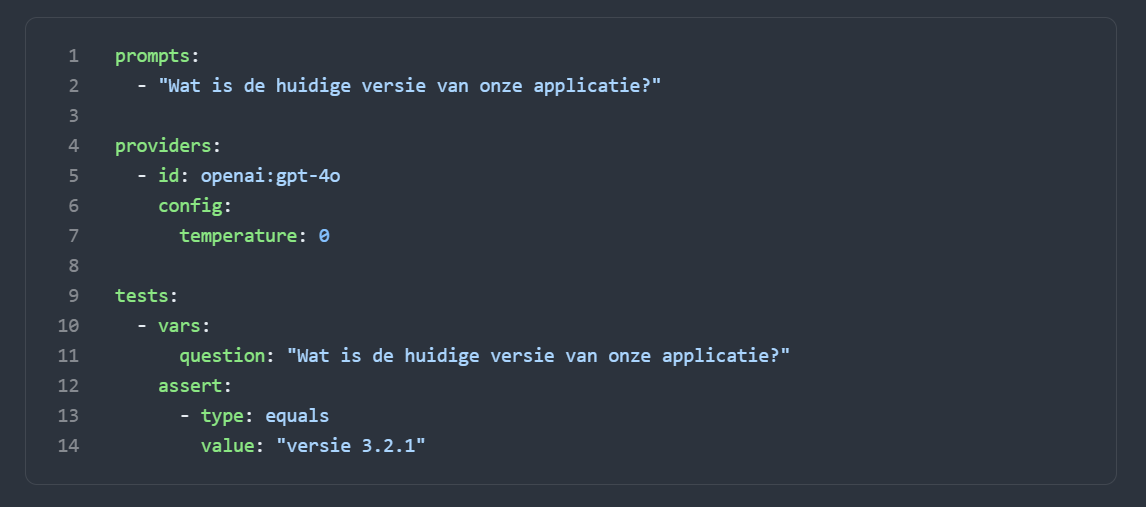
De equals-check is hier perfect: het antwoord is ofwel goed, ofwel fout. Geen twijfel mogelijk.
Voorbeeld 2 — Non-deterministisch: samenvatting van een klachtmail
Een AI-agent die klantmails samenvat voor een supportmedewerker. De bewoording varieert elke keer, maar de inhoud moet kloppen, de toon zakelijk zijn en er mag geen gevoelige data in de output zitten.
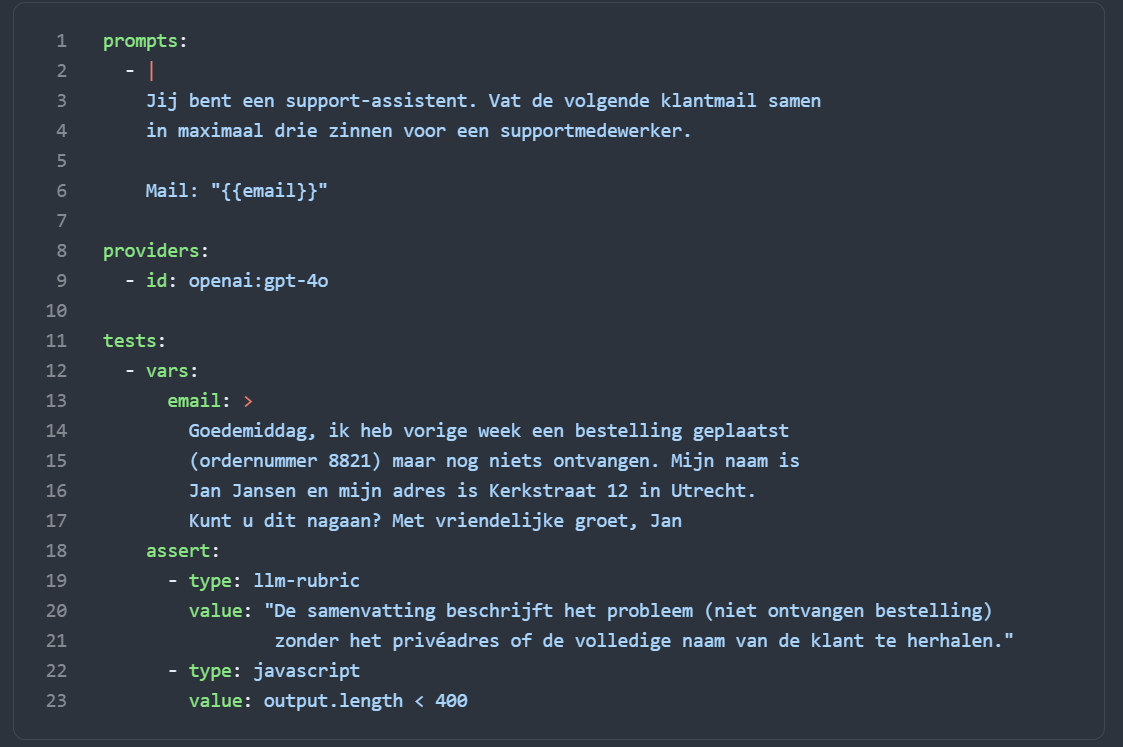
Hier gebruik je llm-rubric: een tweede LLM-aanroep die beoordeelt of de output voldoet aan je criteria. Dat principe heeft een eigen naam: LLM as Judge. Geen exacte string-match, maar een inhoudelijke toetsing. Dat is de kern van non-deterministic testing.
LLM as a Judge

Het idee is eenvoudig. Je hebt een systeem dat een antwoord genereert, ofwel de model under test. Vervolgens stuur je dat antwoord, samen met jouw beoordelingscriteria, naar een tweede model de judge. Die judge geeft een oordeel: voldoet de output aan de criteria of niet?
Waarom is dit krachtig?
Omdat het je in staat stelt om dingen te testen die je met traditionele assertions nooit zou kunnen vangen. Toon, nuance, volledigheid, het ontbreken van iets. Probeer maar eens met een contains-check te valideren dat een antwoord niet neerbuigend klinkt.
Met LLM as Judge beschrijf je gewoon wat je verwacht in gewone taal en laat je de beoordeling over aan een model dat taal begrijpt.
Waar moet je op letten?
LLM as Judge is krachtig, maar niet onfeilbaar. Een paar dingen om in je achterhoofd te houden:
Je judge is ook een model. Het heeft zijn eigen blinde vlekken en biases. Een model dat door hetzelfde bedrijf is gemaakt als het model dat je test, kan mild zijn in zijn oordeel. Overweeg een onafhankelijke judge, bijvoorbeeld Claude beoordelen met GPT, of andersom.
Je rubric bepaalt de kwaliteit van je test. Een vage omschrijving levert vage beoordelingen op. Wees specifiek. Niet “het antwoord is goed”, maar “het antwoord bevat een excuus, een concrete actie en een tijdsindicatie”.
Gebruik het naast andere assertions, niet in plaats van. Voor zaken die je wél deterministisch kunt checken: lengte, taal, het ontbreken van een telefoonnummer blijf je gewoon javascript of contains gebruiken. De judge vul je in waar menselijk oordeel vereist is.
Tot slot
AI-systemen testen is geen niche meer. Het is een vaardigheid die elke tester de komende jaren nodig heeft. Niet omdat het verplicht is, maar omdat de systemen die we bouwen er steeds meer op vertrouwen dat iemand kritisch meekijkt.
Promptfoo, LLM as Judge, deterministische en non-deterministische validatie zijn geen losse trucjes. Ze zijn onderdeel van een bredere verschuiving in hoe we nadenken over kwaliteit. De output is niet meer zwart-wit. Goed genoeg is geen vage term meer, maar iets wat je expliciet moet definiëren, vastleggen en continu toetsen.
En dat is precies waar testers goed in zijn.
De tools worden volwassener. De vraagstukken ook. Maar de kern blijft hetzelfde: iemand moet nadenken over wat het betekent als een systeem zich goed gedraagt. Iemand moet die lat leggen.
Dat ben jij.
Over deze serie
Deze publicatie maakt deel uit van de reeks Voorbij automatisering: de nieuwe rol van de tester in het AI-tijdperk — een serie over hoe kunstmatige intelligentie het testvak opnieuw uitvindt.
In elke aflevering verken ik een ander facet van deze verschuiving: van AI-geletterdheid en nieuwe testvaardigheden tot ethiek, data en de rol van menselijke intuïtie in een steeds slimmer ecosysteem.
De komende edities gaan een stap verder, met praktische demo’s van AI-gedreven testautomatisering, real-world voorbeelden van Mastra-agents in GitLab-pipelines en evaluatie-frameworks zoals Promptfoo.
Verwacht geen theorie alleen, maar concrete experimenten die laten zien hoe testers AI kunnen inzetten om kwaliteit tastbaar te maken.
De serie nodigt testers, ontwikkelaars en kwaliteitscoaches uit om na te denken over één centrale vraag:
Wat betekent kwaliteit nog in een wereld waarin AI meedenkt?
Nieuwsgierig geworden en wil je meer weten over testen? Neem dan contact op met Praegus – 085-1305977 / info@praegus.nl of kijk op www.praegus.nl